Does RTX Use Python? Unlocking GPU Acceleration For Python Developers
Introduction: Decoding the RTX and Python Connection
Does RTX use Python? It's a question that sparks curiosity among developers, data scientists, and tech enthusiasts exploring the cutting edge of computing. At first glance, it seems almost nonsensical—RTX is a brand of powerful graphics cards from NVIDIA, while Python is a versatile, high-level programming language. How could a piece of hardware "use" a programming language? The answer isn't a simple yes or no; it's a fascinating story of synergy, abstraction, and monumental performance leaps. This question really probes the relationship between specialized hardware and the software ecosystems built to harness its power. For anyone working in artificial intelligence, machine learning, data science, or high-performance computing, understanding this connection is no longer optional—it's essential for staying competitive.
The confusion is understandable. We often hear about "Python for data science" or "RTX for gaming and rendering." But the modern computational landscape, especially in AI, is defined by the fusion of these two worlds. NVIDIA's RTX series, with its dedicated RT Cores for ray tracing and Tensor Cores for AI matrix operations, represents a specific hardware architecture. Python, conversely, is the lingua franca of rapid prototyping and scientific computing. The magic happens not because the RTX GPU runs Python code natively, but because a sophisticated software stack allows Python developers to command the immense parallel power of an RTX card with relative ease. This article will dismantle the mystery, exploring the bridge—primarily CUDA—that connects Python scripts to RTX hardware, and why this combination is revolutionary.
Understanding RTX: More Than Just a GPU
What Exactly is an RTX GPU?
To answer "does RTX use Python," we must first demystify what an RTX card is. RTX is NVIDIA's branding for its GPUs that support real-time ray tracing, a rendering technique that simulates the physical behavior of light for incredibly realistic graphics. The hallmark of RTX cards (like the GeForce RTX 4090 or professional RTX A6000) is the inclusion of specialized processing units:
- RT Cores: Dedicated hardware accelerators for calculating the intersections of rays with geometric shapes (BVH traversal), which is the most computationally intensive part of ray tracing.
- Tensor Cores: Specialized circuits designed for performing matrix multiplication and accumulation at high speeds and efficiencies. This is the engine behind DLSS (Deep Learning Super Sampling) and is critically important for AI and machine learning workloads, particularly those involving dense linear algebra.
An RTX GPU is a heterogeneous compute device. It has its own massive number of CUDA cores (for general parallel processing), a high-bandwidth memory subsystem (GDDR6X, GDDR6), and these specialized cores. It doesn't "understand" Python, C++, or any high-level language. It executes low-level machine code, typically compiled from CUDA C/C++ or other GPU-targeting languages via NVIDIA's toolchain. The GPU is a powerful but raw tool; it needs a conductor.
The Hardware-Software Divide: Why Python Can't Run Directly on an RTX Core
Here lies the core of our initial question. No, an RTX GPU does not natively "use" or execute Python bytecode. A Python interpreter runs on the host system's CPU (your Intel or AMD processor). When you write import numpy as np; array = np.ones(1000), that operation is handled by your CPU's main memory and cores. The GPU sits idle unless explicitly instructed otherwise.
The GPU is a separate processor with its own memory (VRAM). To leverage it, you must:
- Transfer data from the CPU's RAM to the GPU's VRAM.
- Launch a kernel—a small program written in a language like CUDA C—that runs in parallel across thousands of GPU cores.
- Retrieve the results back to the CPU if needed.
Writing these kernels from scratch in CUDA C is powerful but complex, requiring deep knowledge of GPU architecture, memory hierarchies (shared, global, constant memory), and thread management. This is where Python comes into the picture not as the language the GPU runs, but as the orchestration language that makes using the GPU accessible.
The Bridge Between RTX and Python: CUDA
CUDA: The Essential Translator
CUDA (Compute Unified Device Architecture) is NVIDIA's parallel computing platform and API model. It is the non-negotiable, foundational software layer that allows software to communicate with and utilize NVIDIA GPUs, including all RTX models. CUDA provides:
- A hardware abstraction layer.
- A runtime and driver API.
- Extensions to standard programming languages (like C/C++) for writing GPU code (
__global__functions). - Libraries optimized for GPU execution (cuBLAS, cuDNN, cuFFT, etc.).
Python cannot directly call CUDA C++ kernels. This is the critical technical hurdle. To bridge this gap, several projects have been created, the most prominent being Numba and the CUDA Python bindings. These tools allow developers to write GPU-accelerated functions using a syntax that looks and feels like Python, which are then Just-In-Time (JIT) compiled to PTX (Parallel Thread Execution) assembly and finally to machine code for the specific RTX GPU.
How Python Libraries Harness RTX Power
The real-world answer to "does RTX use Python" is found in the ecosystem of Python libraries that have built-in, seamless support for CUDA and, by extension, RTX hardware. These libraries handle all the complex data transfer, kernel launching, and memory management under the hood. You, the Python developer, often just need to change an import or a configuration.
- CuPy: This is a NumPy/SciPy-compatible library that uses CUDA to accelerate array operations. Code written for NumPy (
np.dot,np.linalg.eig) can often be run on an RTX GPU by simply changingimport numpy as nptoimport cupy as cp. CuPy manages the GPU memory and calls highly optimized CUDA kernels from its extensive library. - PyTorch & TensorFlow: These dominant deep learning frameworks have first-class CUDA support. When you call
.to('cuda')on a tensor or model, the framework moves the data and computations to the RTX GPU. Their backends are built on cuDNN (CUDA Deep Neural Network library), which is heavily optimized for Tensor Cores. Training a ResNet-50 model on an RTX 4090 can be 50-100x faster than on a high-end CPU, primarily due to Tensor Core utilization. - RAPIDS (cuDF, cuML): An open-source suite of libraries that accelerates data science and analytics entirely on GPUs.
cuDFprovides a pandas-like API for manipulating DataFrames on the GPU.cuMLoffers machine learning algorithms (clustering, regression, etc.) that run at GPU speeds. A typical ETL pipeline that takes hours on a CPU cluster can be reduced to minutes on a single RTX GPU with RAPIDS. - Numba: With its
@cuda.jitdecorator, Numba allows you to write custom CUDA kernels in Python syntax. It's a powerful tool for creating bespoke, high-performance GPU functions when pre-built library functions aren't sufficient.
The Role of NVIDIA Drivers and the CUDA Toolkit
For any of this to work, the system must have:
- The latest NVIDIA drivers for your specific RTX GPU.
- The CUDA Toolkit installed, which includes the necessary compilers (
nvcc), libraries (cuBLAS, cuDNN), and development headers.
The Python packages (PyTorch, CuPy, etc.) are essentially sophisticated wrappers around these low-level CUDA components. They are compiled against a specific CUDA Toolkit version. Mismatched versions are a common source of installation errors. This entire software stack—from driver to toolkit to Python library—is what allows your Python code to "use" the RTX GPU.
Practical Applications: Where RTX + Python Shines
Artificial Intelligence and Deep Learning
This is the undisputed champion use case. RTX Tensor Cores are purpose-built for the matrix math at the heart of neural networks. When you train a large language model (LLM) or a vision transformer in PyTorch on an RTX GPU:
- Mixed-precision training (using
float16andbfloat16) leverages Tensor Cores for 2-3x throughput gains with minimal accuracy loss. - Frameworks like PyTorch automatically compile models via Torch-TensorRT or ONNX Runtime for even more optimized execution on the RTX hardware.
- Inference at scale benefits immensely from the dedicated AI hardware. Deploying a model for real-time video analysis or natural language processing is vastly more efficient on RTX.
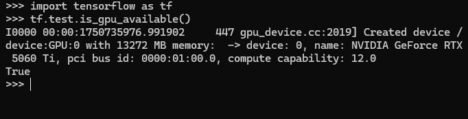
Actionable Tip: When setting up your deep learning environment, ensure you install the CUDA-enabled version of PyTorch from the official PyTorch website. Use torch.cuda.is_available() to verify your Python script can see the GPU. Monitor utilization with nvidia-smi or tools within PyTorch Lightning.
Data Science and Analytics at Scale
Traditionally, data scientists used pandas on a single CPU core, hitting memory and speed walls with large datasets (10GB+). The RAPIDS suite changes this paradigm.
- cuDF loads a CSV directly into GPU memory and performs operations like
groupby,merge, andfilterin parallel across the RTX's thousands of cores. - cuML provides GPU-accelerated versions of scikit-learn algorithms. A K-Means clustering on 10 million rows that takes 30 minutes on a CPU can finish in under a minute on an RTX 3080.
- This enables exploratory data analysis (EDA) on full datasets, not just sampled subsets, leading to more robust insights.
Actionable Tip: Start by converting a slow pandas operation in your workflow to cuDF. The API is intentionally similar. Benchmark the time difference. Be mindful of GPU memory limits; if your dataset is 50GB, a 24GB RTX 4090 won't hold it all, requiring out-of-core strategies or data chunking.
Scientific Computing and Simulation
Fields like computational fluid dynamics (CFD), molecular dynamics, and quantitative finance rely on heavy numerical simulations.
- Libraries like CuPy (as a NumPy drop-in) and scikit-cuda provide GPU-accelerated versions of standard scientific functions (FFTs, linear solvers, random number generation).
- Custom simulation code can be rewritten using Numba's CUDA JIT to run custom stencil calculations or particle interactions on the RTX GPU.
- Monte Carlo simulations, which involve running thousands of independent scenarios, are embarrassingly parallel and ideal for the RTX architecture.
Actionable Tip: Profile your CPU-bound scientific Python code with cProfile. Identify the hottest loops (often NumPy array operations). These are prime candidates for a CuPy port. For custom loops, experiment with a Numba @vectorize or @guvectorize decorator first (which targets CPU/GPU automatically), then move to @cuda.jit for maximum control.
Creative Applications and Rendering
While not strictly "Python programming," the creative pipeline often involves Python scripting.
- Blender Cycles: The open-source 3D suite Blender uses OptiX (NVIDIA's ray tracing engine) for GPU rendering. Python is Blender's scripting language. Artists and technical directors write Python scripts to automate scene setup, asset management, and render farm control. The RTX GPU accelerates the final render, while Python automates the process leading to it.
- Video Encoding/Processing: Tools like FFmpeg can utilize NVIDIA's NVENC encoder (present on RTX cards) for incredibly fast video transcoding. Python wrappers like
ffmpeg-pythonallow you to build complex video processing pipelines that leverage this hardware acceleration.
Addressing Common Questions and Misconceptions
"Can I just pip install something to make my Python code faster on RTX?"
No. There is no magical "RTX accelerator" package. Speed comes from using specific libraries (CuPy, PyTorch, RAPIDS) that are designed to offload work to the GPU. Simply installing cupy won't speed up your existing pandas code; you must rewrite it using the cupy API. The principle is: you must use a GPU-aware library for your specific task.
"Is Python slower than C++ for GPU programming?"
Yes, but the gap is often negligible in practice. A pure CUDA C++ kernel has zero interpreter overhead. A Numba @cuda.jit kernel has some startup cost (JIT compilation) and may not reach the absolute peak optimization of hand-tuned C++. However, for the vast majority of data science and ML workloads, the performance difference is dwarfed by the 50-100x speedup from moving from CPU to GPU. The productivity gain of writing in Python usually far outweighs the minor raw speed loss. For the last 5-10% of performance in a critical kernel, you might write a CUDA C++ extension, but 90% of your codebase can remain in Python.
"Do all Python packages support RTX/GPU?"
Absolutely not. The vast ecosystem of Python (over 400,000 packages on PyPI) is predominantly CPU-bound. GPU support is concentrated in domains where the performance need justifies the complexity: AI/ML (PyTorch, TensorFlow, JAX), Data Science (RAPIDS, CuPy), and some Scientific Computing (Numba, scikit-cuda). A package for web scraping (BeautifulSoup) or web frameworks (Django) will never use your RTX GPU.
"What about AMD GPUs? Can they use Python?"
Yes, but the ecosystem is less mature. AMD's platform is ROCm (Radeon Open Compute platform). There are ROCm-compatible versions of PyTorch and TensorFlow, and a library called CuPy actually supports ROCm as a backend! However, NVIDIA's CUDA ecosystem is vastly larger, better documented, and has wider library support. For a Python developer seeking GPU acceleration, an NVIDIA RTX card currently offers the smoothest, most powerful path.
"Do I need an RTX card, or will any NVIDIA GPU work?"
You need an NVIDIA GPU with CUDA compute capability (most from the last decade). However, to get the full benefit discussed here—especially for AI with Tensor Cores—you want an RTX or newer (e.g., Ada Lovelace, Hopper) GPU. Older GTX cards (like the GTX 1080) have CUDA cores but lack dedicated RT and Tensor Cores. They can still run CUDA code and many Python libraries, but will be significantly slower on AI workloads that can leverage Tensor Cores. For ray tracing or DLSS in games, RT Cores are mandatory.
Building Your RTX-Powered Python Environment: A Practical Guide
- Hardware Check: Ensure you have a compatible NVIDIA RTX GPU. Check the CUDA GPUs list.
- Driver Installation: Download and install the latest Game Ready Driver or Studio Driver from NVIDIA's website.
- CUDA Toolkit: Install the CUDA Toolkit version that matches your target Python libraries' requirements (e.g., PyTorch usually supports the latest 1-2 CUDA versions). Use the network installer or conda for easier management.
- Python Environment: Use conda or venv to create an isolated environment. This is crucial for managing different CUDA versions across projects.
- Library Installation: Install GPU-enabled libraries. For example:
# Using conda (recommended for CUDA dependencies) conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia conda install -c rapidsai -c nvidia -c conda-forge cuml cudf # Or using pip (be sure CUDA is in your PATH) pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 pip install cupy-cuda11x # Replace 11x with your CUDA version - Verification: Run a simple test script.
If this prints your RTX GPU's name, you're ready to accelerate.import torch print(f"PyTorch version: {torch.__version__}") print(f"CUDA available: {torch.cuda.is_available()}") print(f"CUDA device count: {torch.cuda.device_count()}") print(f"Current device name: {torch.cuda.get_device_name(0)}")
The Future: Python, RTX, and Beyond
The integration is only deepening. NVIDIA's Omniverse platform, a 3D simulation and design collaboration tool, uses USD (Universal Scene Description) and has extensive Python APIs. Developers and artists script complex simulations and visualizations that run on RTX hardware. Generative AI—from Stable Diffusion for image generation to LLMs for text—is almost exclusively built and deployed using Python frameworks on NVIDIA RTX (or data center) GPUs.
We are moving towards a future where "GPU-accelerated Python" is the default, not the exception, for any computationally intensive task. The next frontier is unified memory and better just-in-time compilation (like NVIDIA's NVRTC used by Numba) that further abstracts the CPU-GPU data movement, making the experience even more seamless for the Python developer.
Conclusion: The Symbiotic Relationship
So, does RTX use Python? Not in the literal sense. An RTX GPU does not interpret Python code. However, the question reveals a profound truth about modern computing: Python has become the indispensable control plane for unleashing the raw power of specialized hardware like RTX GPUs.
The relationship is symbiotic. RTX hardware provides the brute-force parallel computation and AI-specific acceleration (Tensor Cores) that makes modern AI and large-scale data processing feasible in reasonable timeframes. Python provides the accessible, expressive, and productive language and ecosystem that allows millions of developers, researchers, and scientists to build the applications that feed that hardware. Without the CUDA software stack and GPU-accelerated Python libraries, the RTX GPU would remain a brilliant but underutilized component, mostly confined to gaming and professional rendering. Without RTX hardware, Python's ambitions in AI and big data would be throttled by the limits of general-purpose CPUs.
For the developer, the takeaway is clear: if your Python work involves arrays, matrices, large datasets, or neural networks, investing in an RTX GPU and learning the GPU-accelerated Python stack (PyTorch, CuPy, RAPIDS) is one of the highest-ROI decisions you can make. It transforms your laptop or workstation from a tool that processes data into a machine that interrogates it at the speed of thought. The bridge between "does RTX use Python" is built with CUDA, traveled by libraries, and driven by a community that has made the GPU the most important co-processor of the 21st century. Start building on that bridge today.